From Demo to Decision: Building a Realtime Multi-Agent Voice Assistant for Federal Agencies
How a voice-first, multi-agent architecture grounded in retrieval and observability built trust with federal stakeholders.
Article audio
Listen to this article
This article is long; narration is currently limited to the first 3000 characters.
AI-generated voice.
From Demo to Decision: Building a Realtime Multi-Agent Voice Assistant for Federal Agencies
The Challenge
Federal agencies are curious about AI - but skeptical. In pre-sales conversations with organizations like the VA, IRS stakeholders, and Medicare teams, I kept running into the same wall: leadership wanted to see AI handle their domain with precision, not a generic chatbot regurgitating training data. They needed to trust the answers. They needed to understand what happened when something went wrong. And they needed to see it - live - in 30 minutes or less.
A slide deck wasn't going to cut it. I needed a working system that demonstrated what production-grade AI actually looks like in a government context: domain-specialized, grounded in real content, and fully observable.
What I Built
I forked OpenAI's realtime-agents repo and turned it into a voice-first multi-agent assistant purpose-built for federal use cases.
Instead of one general-purpose bot, the system routes conversations through specialized agents - a VA benefits specialist, a Medicare advisor, an IRS policy agent, and others - each backed by its own retrieval pipeline. Users talk naturally. The system figures out which specialist should handle the question, transfers context seamlessly, and grounds every answer in indexed source content rather than model memory alone.
The core architectural decisions:
- Specialized agents over a monolithic prompt. Each agent carries its own instructions, tools, and retrieval targets. When a topic shifts, the system transfers the conversation - not just the tone - to the right specialist.
- Elastic vector search as the grounding layer. Every agent queries domain-specific Elasticsearch indices using hybrid retrieval (lexical + semantic). Answers come from indexed content, not hallucinated priors. This was the trust story that resonated most with federal audiences.
- Context that survives handoffs. During agent-to-agent transfers, a structured context payload passes the conversation summary and transfer rationale. Users never have to repeat themselves. The backend switches the active agent's instructions, tools, and retrieval targets in a single session update.
- Observability from end to end. OpenTelemetry instrumentation, Elastic APM, and Fullstory session replay are wired together so any failure can be traced from the user's voice input through the tool call, retrieval endpoint, and response - in seconds.
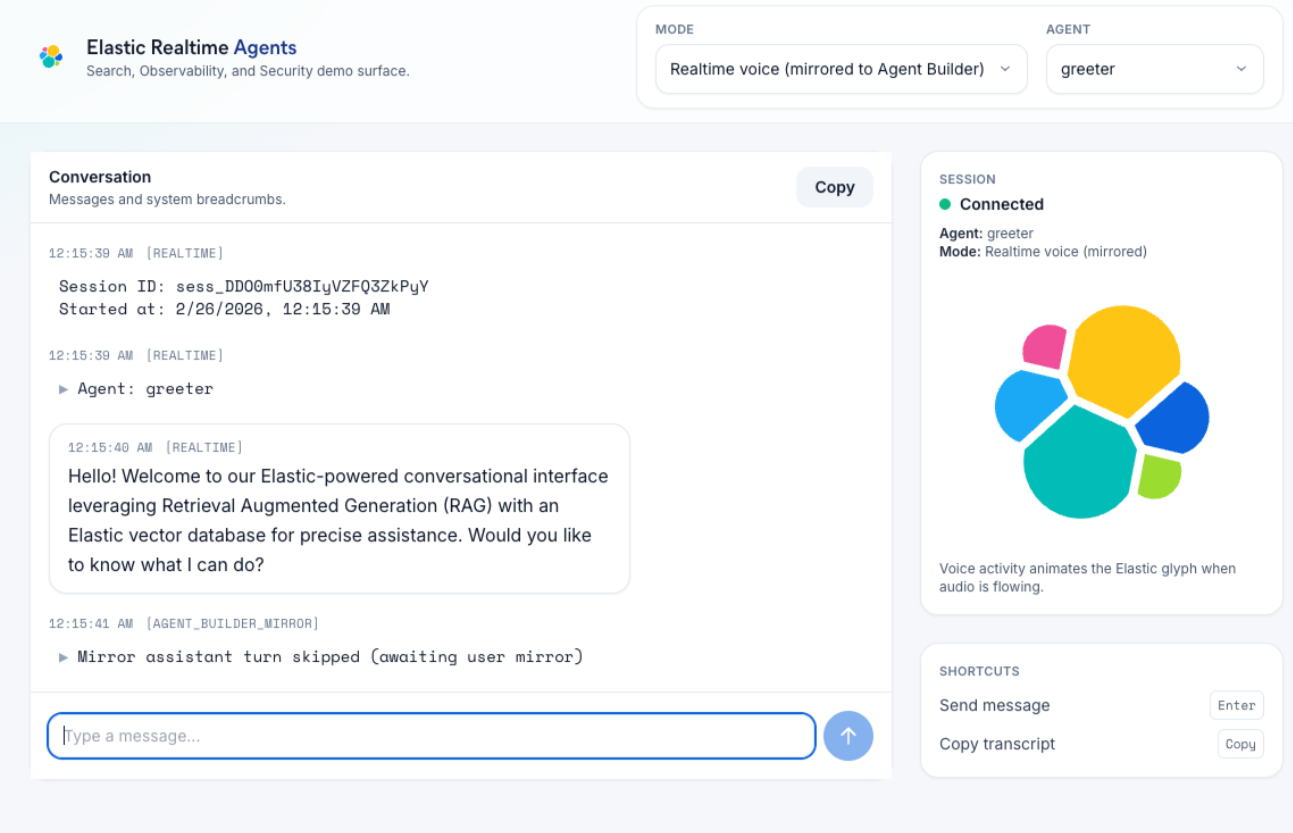 Figure: The realtime multi-agent demo UI used in stakeholder sessions, showing routing context, active mode/agent controls, and live conversation state.
Figure: The realtime multi-agent demo UI used in stakeholder sessions, showing routing context, active mode/agent controls, and live conversation state.
Live Demo
Try the deployed prototype at fedflow.mattcarl.dev.
The Trust Story
This is what made the demo land with federal audiences.
Government stakeholders don't just want a good answer - they want to know where it came from and what to do when it's wrong. Most AI demos dodge both questions. This one addressed them head-on:
"Where did that answer come from?" Every response is grounded in a retrieval step against indexed content. During demos, I could show the actual passages the agent retrieved before generating its response. That turned "the AI said so" into "the AI found this in your documentation and synthesized a response."
"What happens when something breaks?" The observability stack made failures explainable - not just to engineers, but to the room. I could trace an issue from the user's spoken question through the agent routing decision, the retrieval call, and the response generation. In live demos, this turned potential embarrassments into credibility-building moments.
"Can it actually handle our domain?" Agent specialization meant the system didn't try to be everything. When a VA question came in, it routed to the VA specialist querying VA-specific indices. That precision - combined with visible retrieval - consistently shifted the conversation from "is AI ready?" to "how would we implement this?"
Impact
I've demoed this application to executive leadership, 100+ person audiences, technical teams, and individual contributors across multiple federal agencies. Every time, it shifted the conversation forward.
To be clear: this was never a "let's deploy this tomorrow" tool. It was the art of the possible - a working proof of concept that made AI tangible for people making procurement and strategy decisions. The demo established technical credibility fast, built trust through transparency, and consistently moved prospects to the next meeting. In a pre-sales role where the first technical conversation determines whether you get a second one, that's the job.
The pattern it demonstrated - specialized agents, grounded retrieval, full observability - isn't theoretical. It's the architecture production AI systems in government will need to earn and maintain trust at scale.
Architecture Deep Dive
Walk through the core architecture flow and jump straight to each deep-dive section.
System Architecture
flowchart LR
U["User (voice/text)"] --> UI["Next.js Realtime UI"]
UI --> RT["OpenAI Realtime Session"]
RT --> AG["Active Agent Instructions + Tools"]
AG -->|tool call| API["Domain API Routes"]
API --> ES["Elasticsearch Vector / Hybrid Retrieval"]
AG -->|transferAgents| SW["Agent Switch + Session Update"]
SW --> AG
UI --> MIR["Agent Builder Mirror (optional)"]
MIR --> KB["Kibana Agent Builder"]
UI --> TEL["/api/telemetry"]
API --> OTEL["OpenTelemetry (server)"]
TEL --> OTEL
OTEL --> APM["Elastic APM / Observability"]
UI --> RUM["Elastic APM RUM"]
UI --> FS["Fullstory Session Replay"]
FS --> APM
RUM --> APM
Agent Graph & Handoff Logic
Agents are modeled as a directed graph using downstreamAgents. A transferAgents tool is dynamically injected into each agent, constraining transfers to allowed targets. When a transfer fires:
- The destination agent is resolved from function arguments.
- Fuzzy matching and keyword inference are applied against transfer rationale/context.
- The active agent switches.
- A
session.updatereconfigures the Realtime session with the new agent's instructions, tools, and retrieval targets.
This is not a full app reset - it's a controlled session reconfiguration.
Retrieval Architecture
Each specialist agent calls a domain-specific API route:
| Agent | Route | Retrieval Strategy |
|---|---|---|
| VA Specialist | /api/va | RRF: keyword (multi_match) + sparse vector |
| Medicare Advisor | /api/medicare | RRF: keyword + sparse vector |
| IRS Policy | /api/irs | RRF: keyword + sparse vector |
| Elastic Blogs | /api/elasticsearch | Semantic retrieval |
| BioGuide | /api/bioguide | RRF: keyword + sparse vector |
Context Continuity
Two layers maintain coherence across handoffs:
- Realtime conversation memory: Prior turns persist in the same conversation stream.
- Explicit transfer payload: A
conversation_contextfield carries a focused summary of why the destination agent was selected.
In mirrored Agent Builder flows, conversation IDs are isolated per agent to prevent cross-agent context leakage.
Important Note: Agent Switching vs. Model Switching
The model is pinned to gpt-4o-mini-realtime-preview for session creation. What changes at runtime is the active agent's instructions, toolset, and transfer targets. Behavioral specialization comes from orchestration and retrieval, not model hot-swapping.
Observability Stack
- OpenTelemetry: Instrumented on server paths (session creation, tool flows, API routes, mirror/proxy paths).
- Elastic APM: RUM + backend telemetry for request-level and transaction-level visibility.
- Fullstory: Session replay linked to APM context for error-to-user-experience correlation.